Back to Basics: Let Denoising Generative Models Denoise
核心思想
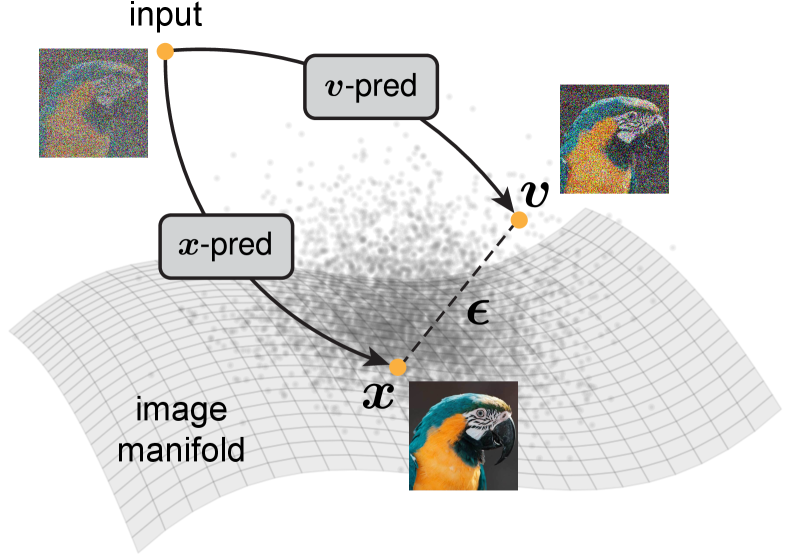
扩散模型应该直接预测什么?传统方法预测噪声 $\boldsymbol{\varepsilon}$ 或速度 $\mathbf{v}$,本文基于流形假设论证:应该直接预测干净图像 $\mathbf{x}$。
核心论点:自然图像位于高维空间中的低维流形上,$\mathbf{x}$ 是 on-manifold 的(低维),而 $\boldsymbol{\varepsilon}$ 和 $\mathbf{v}$ 是 off-manifold 的(高维)。对于有限容量的网络,预测低维目标更容易。
提出 JiT (Just image Transformers):标准 ViT 直接在原始像素上做 x-prediction,无需 tokenizer、预训练或辅助损失。
方法详解
1. 扩散基础公式
1.1 线性插值
\[\mathbf{z}_t = t\mathbf{x} + (1-t)\boldsymbol{\varepsilon} \tag{1}\]注意本文的时间方向:$t=0$ 为噪声,$t=1$ 为数据(与某些 convention 相反)。
1.2 速度场
\[\mathbf{v} = \mathbf{x} - \boldsymbol{\varepsilon} \tag{2}\]1.3 v-loss
\[\mathcal{L} = \mathbb{E}_{t, \mathbf{x}, \boldsymbol{\varepsilon}} \|\mathbf{v}_\theta(\mathbf{z}_t, t) - \mathbf{v}\|^2 \tag{3}\]1.4 生成 ODE
\[\frac{d\mathbf{z}_t}{dt} = \mathbf{v}_\theta(\mathbf{z}_t, t) \tag{4}\]从 $t=0$(噪声)积分到 $t=1$(数据)。
2. 预测空间 vs 损失空间的分离
关键 insight:预测 ${\mathbf{x}, \boldsymbol{\varepsilon}, \mathbf{v}}$ 中的任何一个,配合适当的损失空间转换,数学上等价。但维度特性完全不同。
2.1 x-prediction 约束系统
\[\begin{cases} \mathbf{x}_\theta = \text{net}_\theta(\mathbf{z}_t, t) \\ \mathbf{z}_t = t\mathbf{x}_\theta + (1-t)\boldsymbol{\varepsilon}_\theta \\ \mathbf{v}_\theta = \mathbf{x}_\theta - \boldsymbol{\varepsilon}_\theta \end{cases} \tag{5}\]由此推导:
\[\boldsymbol{\varepsilon}_\theta = \frac{\mathbf{z}_t - t\mathbf{x}_\theta}{1-t}, \quad \mathbf{v}_\theta = \frac{\mathbf{x}_\theta - \mathbf{z}_t}{1-t}\]2.2 x-prediction + v-loss(本文采用)
\[\boxed{\mathcal{L} = \mathbb{E}_{t, \mathbf{x}, \boldsymbol{\varepsilon}} \left\|\frac{\text{net}_\theta(\mathbf{z}_t, t) - \mathbf{z}_t}{1-t} - \mathbf{v}\right\|^2} \tag{6}\]等价于加权 x-loss:$\mathcal{L} = \mathbb{E}\left[\frac{1}{(1-t)^2}|\mathbf{x}_\theta - \mathbf{x}|^2\right]$
为什么 x-prediction + v-loss 而不是 x-loss? v-loss 提供了更好的时间加权——在 $t$ 接近 1 时(近数据端)权重更大,更关注精细细节。
3. 流形假设的实验验证
Toy 实验:2D 数据嵌入到 $D$ 维空间($D \in {2, 8, 16, 512}$)
| 维度 D | x-prediction | ε-prediction | v-prediction |
|---|---|---|---|
| 2 | ✓ | ✓ | ✓ |
| 8 | ✓ | ✓ | 轻微退化 |
| 16 | ✓ | 崩溃 | 崩溃 |
| 512 | ✓ | 灾难性崩溃 | 灾难性崩溃 |
ImageNet 256×256(JiT-B/16, patch 维度 768):
| 预测目标 | 损失空间 | FID ↓ |
|---|---|---|
| x-prediction | v-loss | 8.62 |
| x-prediction | x-loss | 10.14 |
| ε-prediction | 任意 | 372~394 |
| v-prediction | 任意 | 96~127 |
ε/v-prediction 在 768 维 patch 空间中完全崩溃。
4. JiT 架构
标准 ViT,无特殊设计:
- 图像切分为 $p \times p$ patch → 线性嵌入 → 位置编码 → Transformer blocks → 线性输出
- 条件化:adaLN-Zero(时间 $t$ + 类别标签)
- 增强:SwiGLU、RMSNorm、RoPE、qk-norm、in-context class tokens
4.1 瓶颈嵌入
不让隐藏维度等于 patch 维度,而是加入低秩瓶颈层(如 128 维):
| 瓶颈维度 d’ | FID ↓ |
|---|---|
| 768(无瓶颈) | 8.62 |
| 512 | 7.88 |
| 256 | 7.62 |
| 128 | 7.48 |
| 32 | 7.85 |
瓶颈鼓励低维表示学习,FID 提升 1.14 点。这进一步验证了流形假设。
5. 高分辨率扩展
x-prediction 解耦了网络架构与观测维度:patch 维度可以很高,但网络通过瓶颈在低维空间工作。
| 分辨率 | Patch 大小 | Patch 维度 | FID ↓ | GFLOPs |
|---|---|---|---|---|
| 256×256 | 16 | 768 | 4.37 | 25 |
| 512×512 | 32 | 3072 | 4.64 | 26 |
| 1024×1024 | 64 | 12288 | 4.82 | 30 |
序列长度固定为 256,计算量几乎相同。
实验结果
ImageNet 模型缩放(600 epochs)
| 模型 | 256×256 FID ↓ | 512×512 FID ↓ |
|---|---|---|
| JiT-B | 3.66 | 4.02 |
| JiT-L | 2.36 | 2.53 |
| JiT-H | 1.86 | 1.94 |
| JiT-G | 1.82 | 1.78 |
JiT-G 在 512×512 上达到 FID 1.78,无需 tokenizer、预训练或辅助损失。
架构消融(累积改进)
| 改进 | FID ↓ | FID w/ CFG |
|---|---|---|
| Baseline (SwiGLU, RMSNorm) | 7.48 | 6.32 |
| + RoPE, qk-norm | 6.69 | 5.44 |
| + in-context class tokens | 5.49 | 4.37 |
个人思考
- 流形假设的力量:一个简单的观察($\mathbf{x}$ 低维,$\boldsymbol{\varepsilon}$ 高维)产生了巨大的实际影响——在 768 维空间中 ε-prediction 完全失败。
- 瓶颈层的反直觉效果:压缩到 128 维反而比 768 维更好,强力支撑了流形假设。
- 极致简洁:JiT 的设计哲学是去掉一切不必要的组件(tokenizer、预训练、辅助损失),只保留 ViT + x-prediction。
- 为 pMF 和 iMF 奠基:JiT 的 x-prediction 思想被 pMF(像素 MeanFlow)和 iMF 继承和扩展,形成了完整的方法体系。
- 1024×1024 的可行性:patch 维度高达 12288 时仍然工作,这在 ε/v-prediction 中完全不可想象。